
End-to-end automation potential when ITSM is part of the game
Background
We, the authors of that article, Dennis and Michael have a common past. We both worked a while ago for a big international Swiss bank, where we gathered extensive experience around operational structure, typical challenges and hurdles and needed to find a way around them.
Some time later we are working for ServiceNow and Red Hat, two leaders, one in ITSM and another in open source (automation) software. We teamed up with Faruk, a Security Advisory Solution Architect to cover the most purposeful and relevant points of what benefits automation brings to you, what to focus on and why automation is a major factor when it comes to security.
So, let’s start with the basics.
The basics
Of course there are other ITSM and automation systems out there, but it is also hopefully not a surprise giving our background that we will exclusively focus in this blog on these two systems:
- ServiceNow, a SaaS/PaaS platform that allows organizations to automate all aspects of the IT processes like operations management, project, security, Hard/Software asset management and IT and Service Management (request, Incident, problem, change management, etc.). To support those processes ServiceNow also includes the CMDB (component management database). ServiceNow also supports other workflows in other domains outside IT but those will not be discussed in this blog.
- Ansible Automation, a foundation for building and operating automation across an organization, including all the tools needed to implement enterprise-wide automation
If working with ServiceNow and Ansible Automation you have even more potential we want to bring to your attention. You for sure heard about DevOps and most probably about DevSecOps. And some of you maybe even started an automation journey. But in rare cases people think how I could integrate my ITSM system into my automation journey. And even less know about the huge potential if you do so. Meanwhile Red Hat even released the ServiceNow certified content collection. An interface from Ansible Automation to ServiceNow which comes along with a broad catalog of methods and functions and all supported end to end by Red Hat.
So let’s have a look at the teamplay of these two systems.
Two new old best friends
Let’s take an incident handling perspective to bring things in context:
Managing incidents, change requests and problem tickets effectively, tooling considered most effective by many is ServiceNow. Same is true with infrastructure automation for Red Hats Ansible Automation Platform.
Real power comes from a combination of both tools, and we want to surprise you by showing how powerful they will feel from an end to end perspective.
Let’s try to understand what can trigger a deployment or a remediation task. Human errors are the most common root cause of incidents.1 This is by far no surprise, but it is the fundament of what urges us to address this document. In ServiceNow issues are managed through (security) incidents, changes are managed through Change Request and alerts are managed through Event Management. All those ITIL processes are managed in an automated way using flows. Those flows are managing the governance, meaning involving the right people, assigning tasks to the right people, enriching the process with data for automated decisions and doing root cause analysis if possible, managing the approvals and so on. When this must be done manually then it is time consuming, and mistakes can easily be made. By automating this we gain time on different fronts and reduce MTTR.2
MTTR = Starting from detection it is the time of diagnosis + repair.
This is where the one workflow concept can support you end to end and can be implemented for each IT use case. These can be very easy ones like a DB table space extension for a test stage up to a certificate renewal on a productive system.
At the end the operational work must be done, and this is where Ansible Automation will step in. Thanks to bidirectional integration both systems can be synced and leverage each other’s strength. In our DB table space example this would not only mean that ServiceNow took Ansible Automation to execute the change but Ansible communicated the change back to ServiceNow for full tracking purposes and what was done where, via documenting it in a change request.
Let’s take the Incident use case.
Incident use case
When the workflow for the incident wants to trigger a playbook then this can be easily done by the workflow but when the playbook is done then Ansible can update the Incident ticket accordingly and close it when necessary. Just a simple example where ServiceNow automates governance and Ansible will automate operations. Another benefit is that the full history of the Incident including resolution is available as one system of record and can be used as part of your knowledge system. We explain that this concept of automating governance and operations as one workflow can be applied to any type of use case.
The below diagram is just an example of the possibilities that we can do between those two systems. Flows and playbooks can easily be adapted to any type of use case and thanks to the bidirectional integration between systems works as one system and leverages each other’s strengths. At the end there could be use cases that are coming from operations, DevOps, Customer Service, Service Management, Software Asset Management and so on.
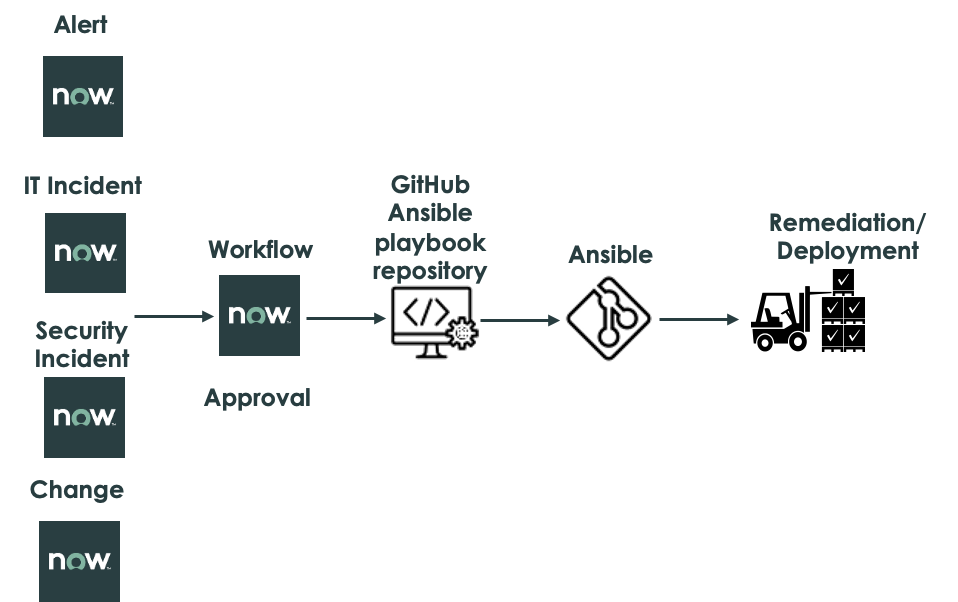
The role of governance
The goal to achieve through governance is to create traceability, accountability, visibility, auditability, and transparency and understand the impact (risk) of a change. Let’s try to understand this in detail.
- Traceability = Where is the change coming from, how is that being created, what are the changes compared with last time/release and where is it deployed?
- Accountability = Who approved/rejected this change and why it was approved/rejected?
- Visibility = When and where do we deploy this and what do we deploy exactly?
- Auditability = Who executed the change and where was this change executed?
- Transparency = Everybody that is involved understands the change and when the change takes place!
- Impact/risk = Who and what’s being impacted by this change?
Also the order of the above objectives matter. They help us to progress fast on achieving the final paramount goal: Minimize outages, solve issues faster (MTTR), improve / automate handovers to production and most importantly we create historical data that can help us to improve.
Manual processes do not help to create a governance setup that addresses today’s complex, deeply integrated and fast changing IT landscapes and business needs. Manual processes always lead to systems being disconnected, bad process quality from a time, throughput and result point of view – and even more important: People were disconnected, felt helpless and lost motivation.
Formal governance is hindering progress and flexibility, as automated governance does enable people and organisations: our goal is to automate governance and act as one workflow across systems, processes and people. That is why the combination of both systems is so important.
This enables us to create a system of record for change that covers all those 6 points. That system of record for change that contains all the governance is ServiceNow but enriching all activities data from Ansible. That record will contain all change process data and we will see with the DevSecOps use case that we can include more like the full life cycle data from a release process into this change record to achieve those 6 six points.
Ansible Automation and ServiceNow continue to be best of breed choice
The approach to have a close cooperation between ServiceNow and Ansible is indeed not new. But what changed is the release of the Red Hat Ansible Certified Content Collection for ServiceNow3 in summer 2020. Ansible Automation (with some help from existing Ansible content) can automate just about any task, while the modules from this Certified Collection allow us to keep the ServiceNow information up to date.
The Certified Collection was designed and developed by the XLAB Steampunk team4 in close collaboration with Red Hat Ansible, specifically keeping end-users in mind.
With Red Hat Ansible Certified Content Collection for ServiceNow ITSM, you can:
- Automate change requests. Use Ansible Playbooks to automate ServiceNow ITSM service requests, including reporting change results and all information related to those changes. Your service representatives can simply kick off an Ansible Playbook to resolve common requests and reduce rote, repetitive tasks.
- Automate incident response. Assets in the ServiceNow Certified Collection support automatic updates to incident tickets to provide a consistent audit trail. Your team can also streamline the required steps for issue remediation and apply them at scale.
- Enable full “closed loop” automation. Simplify the opening, advancement, and resolution of IT service management workflow items while keeping relevant and accurate information flowing into the CMDB across disparate users, teams, and assets. Ensure that infrastructure information is always up to date, actionable, and auditable while work is completed by cross-domain teams that may or may not have access to ServiceNow.
Code examples
We want to show you here some code snippets that you get an idea how this can look like on the ground:
Managing incidents, the Ansible way5
Creating a new incident ticket using Ansible is reasonably straightforward, but before we can do that, we need to tell Ansible where our ServiceNow instance lives and what credentials to use. We will do that by setting three environment variables:

Now that we have our credentials ready, we can create a new incident. The minimal Ansible playbook would look something like this:

Updating the CMDB5
Let’s imagine we created a new VM instance with Ansible and want to register it to the CMDB of ServiceNow.
Because the ServiceNow CMDB has more than one configuration item type, we need to specify the sys_class_name parameter when adding new items. By default, the servicenow.itsm.configuration_item module will use the cmdb_ci system class name, but we can change it to any other cmdb_ci-derived class.
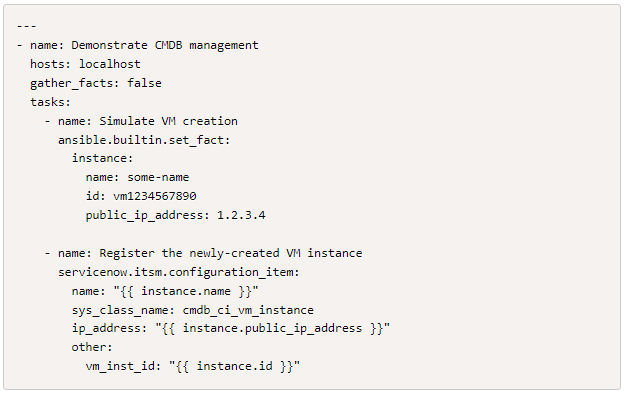
We used the generic other parameter that can contain arbitrary key-value pairs in the last task. Because ServiceNow tables are extensible, all modules have this parameter. We can use the other parameter to set column values that modules do not expose as top-level parameters. All ServiceNow Ansible modules have this parameter.
Key take aways
Let’s try to summarize the blog in three major statements:
a) Governance needs to be automated and is driven by a (change) record that needs to be both managed and executed in one, fully automated process.
b) Service Now and Ansible Automation are two well harmonizing, yet individual specialised tools to achieve such an automation.
(c) Manual governance instead is the reason why governance as a term has such a bad reputation.
By leveraging both systems’ strengths you will have your IT amplifier that accelerates automation and improves IT processes. The one workflow approach will give you those six points as discussed in the blog traceability, accountability, visibility, auditability, transparency and Impact/Risk.
Those points will reduce outages percentages. Of course, there will be outages but even then, you will improve damage control because of those six points. We can say that we can deliver with the speed of light but we are still in control of what we deploy.
Sources
Blog references
[1] Statement is based on project experience
[2] Mean time to recover, https://en.wikipedia.org/wiki/Mean_time_to_recovery
[3] https://www.redhat.com/en/resources/ansible-certified-content-collection-for-servicenow-overview
[4] https://steampunk.si
[5] Extracted out of the blog: https://www.ansible.com/blog/certified-collection-servicenow
Additional links
Red Hat Summit 2021 Webcast around ServiceNow and Ansible Tower, done together with DXC: LINK
Beitrag vom 2ten Ansible Anwendertreffen, ebenfalls zusammen mit der DXC: LINK
Authors

Dennis Kuipers
Senior Solution Consultant @ ServiceNow
https://www.linkedin.com/in/dennis-kuipers-a48723

Faruk Gündemir
Advisory Solution Consultant Security Operations @ ServiceNow
https://www.linkedin.com/in/faruk-g%C3%BCndemir-64358420
Other supporters from Red Hat: Götz Rieger, Karoly Vegh and Michael Leibfried