Abstract of our book about how to develop, build, deploy, and run applications on Kubernetes
In March 2021, we both embarked on a thrilling journey by writing a book on “Kubernetes Native Development – Develop, Build, Deploy, and Run Applications on Kubernetes”. The book covers a topic that is especially relevant for everyone that decided to adopt Kubernetes as the core of their (hybrid) cloud strategy and strive to leverage its full potential right from the beginning of developing an application. What we present in this article is three-fold: firstly, we are going to take you on a 10k feet flight over the topics discussed in our book, which is really a practitioner’s guide and completely based on upstream Open Source projects. Secondly, we will introduce our running example that is freely available on github.com. Thirdly, we conclude this article with an outlook on another topic that instantly follows from what we will describe here: How can OpenShift help when running, developing, building, and delivering a Kubernetes native application?

What is Kubernetes-native?
Before we start, let us briefly elaborate on the term “Kubernetes-native”. What makes an application Kubernetes-native and how do we develop in a Kubernetes-native way? You might know the term “Cloud-native application” which is according to Bill Wilder an application that fully leverages the advantages of a cloud platform. We can thus similarly conclude that a “Kubernetes-native” application is an application that fully leverages the advantages of Kubernetes. Instead of reinventing the wheel, a Kubernetes-native application makes use of Kubernetes capabilities whenever possible and reasonable. Examples are auto-scaling, configuration management, rolling updates, and self-healing. Kubernetes-native development makes use of Kubernetes capabilities during the whole development lifecycle phases: plan & design, code, build, deploy, run, and monitor. Hence, it is not a surprise that we decided to structure our book accordingly.
Running example – Local News
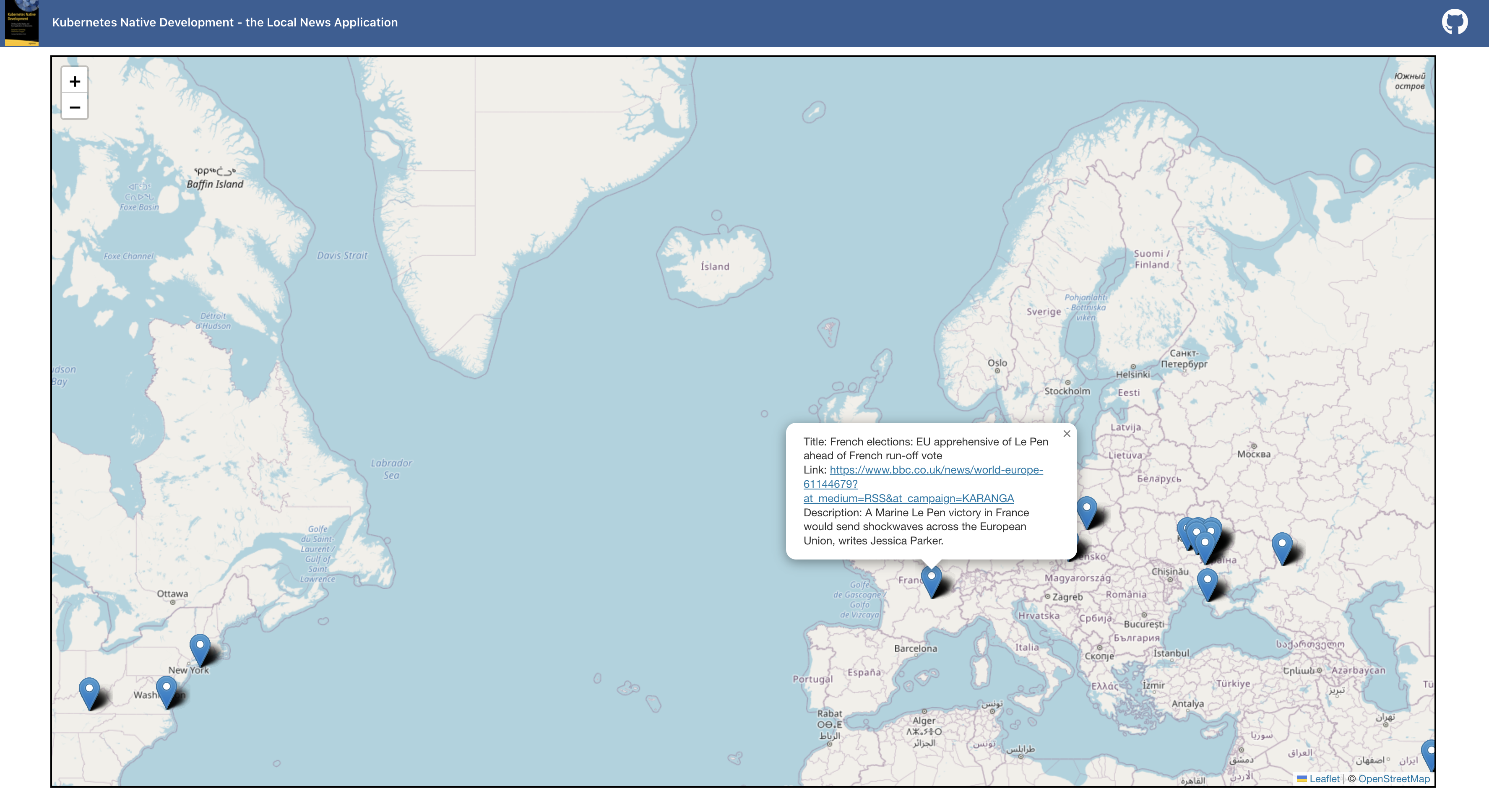
To illustrate the described concepts in our book and make them more tangible, we introduce a running example that will accompany you throughout the entire development lifecycle. The application implements the following use case: Identify locations in the description of a news feed to pin it on a map so that the user can see news near his current spot. To add the missing geographical coordinates to the news elements, we use natural language processing to determine the location in the text and retrieve the coordinates. To achieve this, we implemented several components based on different types of languages using different kinds of frameworks. The public Git repository https://github.com/Apress/Kubernetes-Native-Development contains the source code accompanying this book. Let us now take a closer look at the structure of our book.
Journey through our book
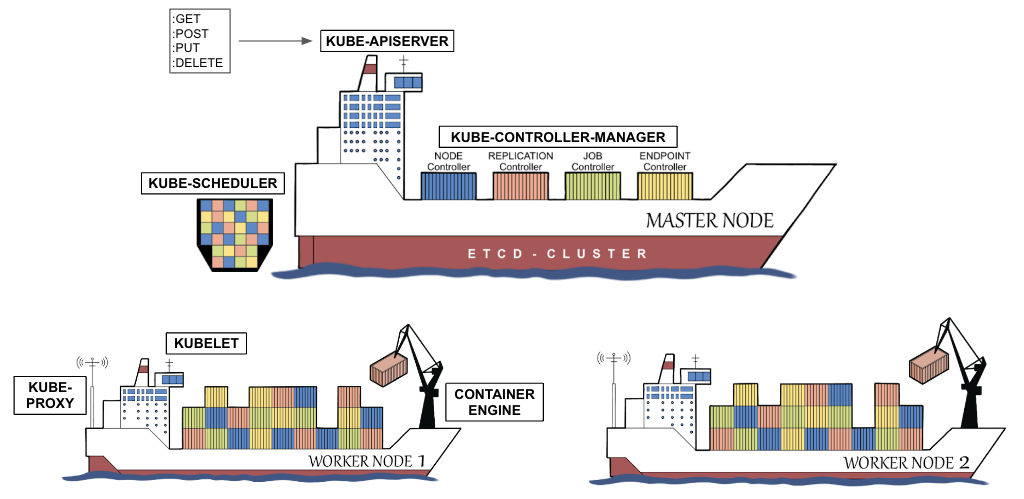
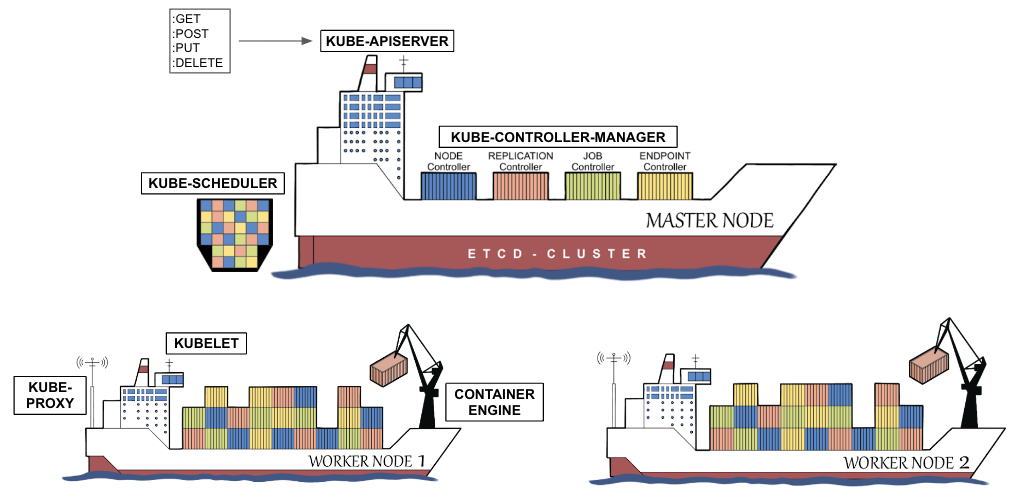
In the first chapter, “The Impact of Kubernetes on Development”, we give a head start on Kubernetes explaining its architecture as well as the most important concepts such as Containers, Pods, ReplicaSets, Deployments, Services, etc. For each concept, more specifically, resource type, we supply a practical example that you can run yourself on a Kubernetes environment of your choice (for instance, Minikube). We discuss the impact of the resource types by comparing them to the pre-Kubernetes era.
Application Design Decisions
After laying the foundations, we discuss various “Application Design Decisions” -in Chapter 2- to be made when you are planning to develop a new application that should run on Kubernetes. This involves, on one hand, architectural decisions on the system architecture layer such as how to split your application into several components. On the other hand, you should take care of the software architecture that determines how to organize and modularize your source code.
In the second part of the chapter, we discuss various technical decisions to be made, e.g. the programming language of choice, and, depending on this, the runtime environment and frameworks to be used. All these aspects are thoroughly thought-through with Kubernetes as the target runtime environment. We conclude the chapter with a brief excursion on non-functional requirements for Kubernetes-native applications.
Development Approach
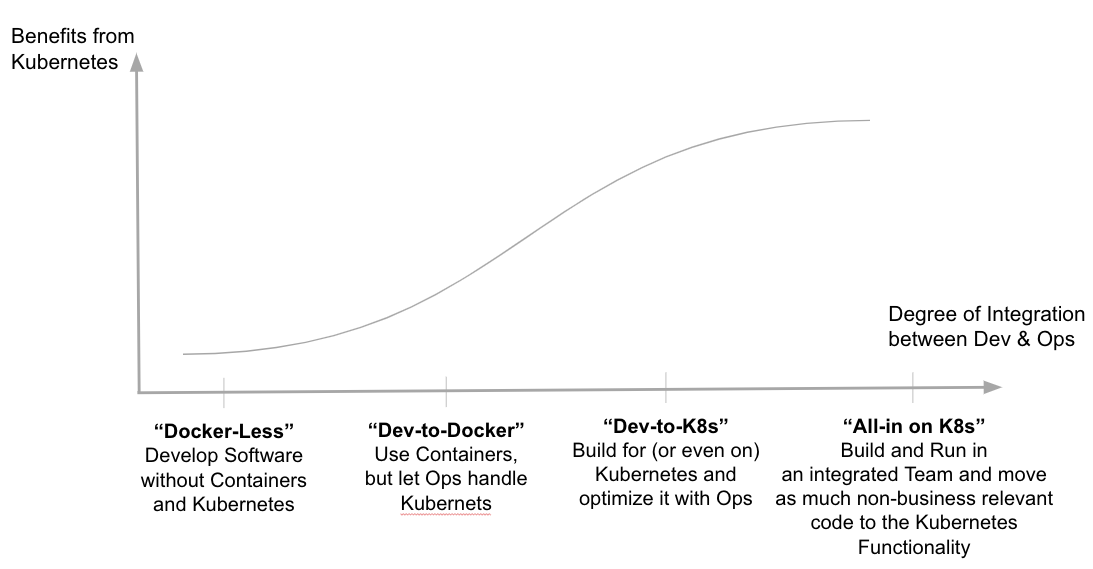
Chapter 3 “Developing on and with Kubernetes” delves into the inner-loop development process and presents three approaches with different levels of integration into the underlying Kubernetes environment. From “Docker-less” to “Dev-to-Docker” and finally “Dev-to-Kubernetes” we outline the benefits and limitations of the respective approaches and give some examples to get your hands dirty with each approach. In the last approach, where the developer is fully aware of Kubernetes making use of it during the development, we demonstrate how to develop locally and run the code on Kubernetes as well as to develop directly on Kubernetes.
Kubernetes-Native Applications
The fourth chapter “Writing Kubernetes-native Applications” shifts the perspective from the development approach back to runtime aspects of the application itself and how it can leverage the different Kubernetes capabilities. It explains how to retrieve reflective information from Kubernetes as the execution environment – e.g. aspects such as what is my IP address or is there a specific Kubernetes label the application should act upon.
In the second part of the chapter, we explain how to define custom Kubernetes resource types and how to access this information from within your application. This can be tremendously helpful for configuration and administration purposes.
Kubernetes-Native Pipelines & GitOps
Once we push our code into a code repository, we leave the inner development loop to shift from an individualized development environment into a continuous integration environment. Chapter 5, “Kubernetes-native Pipelines”, demonstrates how to build your application in an automated and thus reproducible manner. It starts with Kubernetes-native pipelines based on Tekton and combines it with GitOps as a declarative deployment approach based on a single source of truth residing in your code repository.
Operators
The last chapter concludes our journey through the world of Kubernetes-native development by shifting our view more to the operational side of the coin. We introduce the concept of operators, a means to put operative knowledge into code, and describe how to develop your own operator that accompanies your application to automate various operational aspects. There are several flavors of how to develop such an operator. We describe two of them: An operator based on Helm and an operator based on Go. But when an operator manages the application, who will actually manage the operators? We will talk about this at the end of our book and conclude it by finally bringing the two concepts –operators and GitOps– together.
Outlook – What about OpenShift?

But wait a second, we, the authors, are both working for Red Hat. Hence, the following question should quite obviously be answered: How can we run this application not only on plain Kubernetes but on OpenShift? What has to be changed and why? What are the benefits when moving from Kubernetes to OpenShift? This will be the topic of a series of articles titled “You wrote a Kubernetes-native Application? Here is how OpenShift helps you to run, develop, build and deliver it – securely!” So stay tuned….
Authors
Benjamin Schmeling
Benjamin Schmeling is a solution architect at Red Hat with more than 15 years of experience in developing, building, and deploying Java-based software. His passion is the design and implementation of cloud-native applications running on Kubernetes-based container platforms.
Maximilian Dargatz
I am Max, live in Germany, Saxony-Anhalt, love the family-things of life but also the techie things, particularly Kubernetes, OpenShift and some Machine Learning.