
Open source has become widely adopted as a default, making it easy to overlook its significance in the field of Data science. There is a need to appreciate the greater value in this area. Data scientists can enhance efficiency and improve work performance by utilizing Open source tools and frameworks, unlocking their full potential through customization. By creating awareness around the benefits of Open source, we can encourage data scientists to think more deeply about how they can leverage it to achieve their goals. It has the potential to shake up how Data science is applied in a variety of ways, such as developing more precise models and dealing more efficiently with larger datasets.
Open source has played a central role in Data science up to now, but it is crucial to realize that Open source in the Data science field, is facing new challenges. In a commercialized world, there is the risk of breaking away from its principles. In spite of these challenges, Open Source continues to be an essential element for democratizing and promoting collaboration in this field. In addition to overcoming existing challenges, it is important to accelerate research on the use of Open Source solutions in order to bring about a greater diversity within the Data Science community.
Why is Open Source important for the Data Science field?
The Data Science community has come to value Open Source software for its many benefits. First, it has accelerated the expansion of the ecosystem by providing a base for Data scientists to interact, exchange ideas, and contribute to ongoing activities. This promotes innovation and leads to the development of better technology and tools for data analysis. Second, Data scientists can enhance models that can be applied to different projects thanks to open source. Consequently, improving upon available models saves time and effort when compared to creating new ones from the start because they can be continuously further improved and made available to others. Last but not least, the open source spirit of cooperation is crucial because it enables developers and data scientists to efficiently collaborate on projects and to achieve common goals. This in turn contributes to creating and maintaining a vibrant community that shares knowledge, resources, and experience. Overall, this area has been transformed by Open Source software through the democratization of tool access, the promotion of innovation, and the encouragement of teamwork.
Where we are nowadays – Data Science Lifecycle
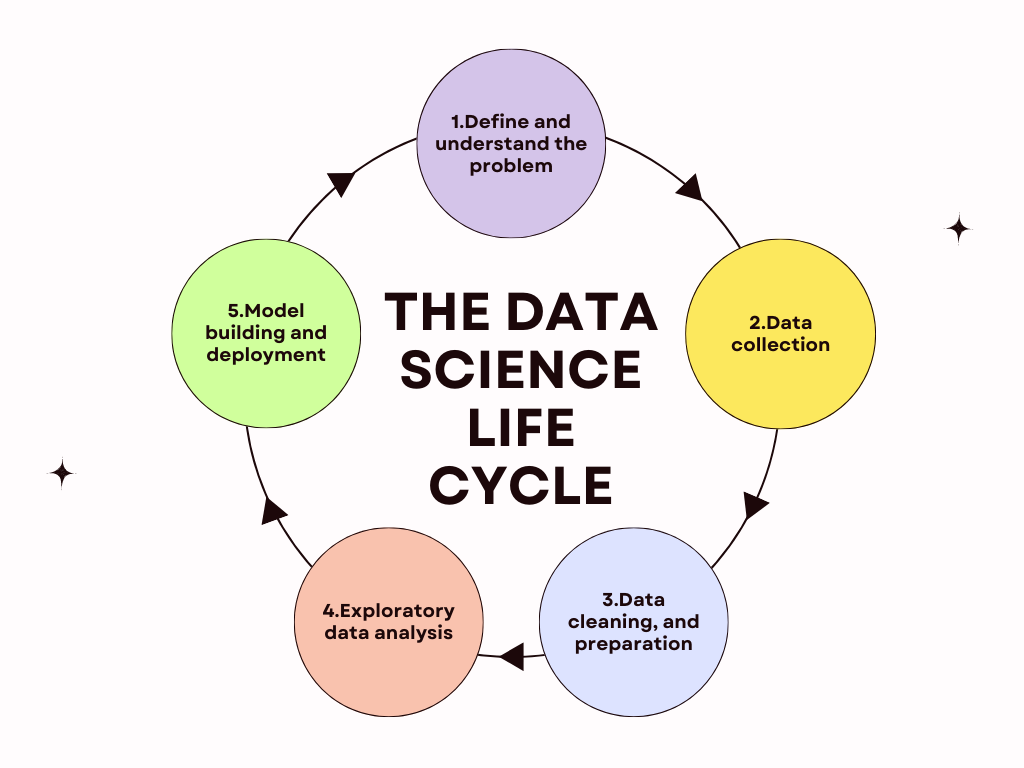
The Data Science lifecycle process comprises five key stages: Business Understanding, Data Acquisition, Modeling, Deployment, and Customer Acceptance. A detailed comprehension of the client’s business challenge is necessary to get the process started. For example, to predict the loss of customers in the domain of retail, it is critical to understand the client’s business, needs and expectations. Engaging subject matter experts helps identify underlying problems. Usually, a business analyst collects data from the client and sends it to a team of data scientists for analysis.
Once the problem is clearly defined, the next step is gathering relevant information and breaking down the problem into smaller components. Identifying data sources, such as web server logs and digital libraries, is the initial phase of a data science project. Data collection involves obtaining information from reputable internal and external sources, using methods like third-party APIs or web scraping with Python.
Next, data preparation includes selecting relevant data, cleaning it, merging it with other data sets, treating missing values by removing or changing them, purging incorrect information, and identifying and addressing outliers. Feature engineering can be used to create new data and extract new features from existing ones. Any unnecessary columns or functions should be eliminated, and the data needs to be formatted based on the model’s requirements.The longest and most important step across the entire life cycle is data preparation.
Moving to the modeling phase, the provided data serves as input, and the goal is to create the desired result. Depending on the problem type—regression, classification, or clustering—the appropriate machine learning algorithm is chosen. Adjusting hyperparameters is crucial to achieve desirable results. Model assessment follows, evaluating accuracy and correctness.
Finally, the tested and validated model is deployed to a production environment, such as a server or cloud platform, for making predictions on new data. The deployment stage involves testing, packaging, and performance monitoring. The ultimate goal is to utilize the information extracted from the data to enhance business operations — a critical step for companies leveraging data science.
Sharing fundamental methods / technologies – What do Data Scientists need?
Data science is a rapidly evolving field that requires a deep understanding of mathematical, statistical, and computational principles. However, regardless of the specific use case or industry, there are fundamental methods and technologies that apply universally. For instance, data cleaning and preprocessing, exploratory data analysis, feature selection and model validation are crucial steps that must be carried out in every data science project.
Data scientists often need GPUs for model training, which might not always be easily accessible as an Open source product. However, using libraries that support GPUs can provide a solution. GPUs significantly accelerate the training of neural networks in deep learning, contributing to rapid progress in the field. Popular open-source tools like TensorFlow, PyTorch, and CUDA support GPU acceleration, making deep learning models faster and more efficient.
Access to data services is critical in data science, particularly for big data, where large volumes of data are generated and stored in various formats. Open-source tools like Apache Hadoop and Apache Spark streamline data access, providing distributed computing frameworks with support for accessing data from various sources. Other tools like Apache Kafka and Apache NiFi enable real-time data ingestion and streaming, facilitating data collection and analysis. Platforms like Kaggle host public datasets, and there are many other open-source datasets available for analysis.
Common programming languages (Python, R, SQL) and popular libraries/frameworks (Pandas, NumPy, Scikit-learn, TensorFlow) are widely used in data science applications. Sharing these methods and technologies allows data scientists to collaborate efficiently and create transferable solutions. Various open-source platforms, such as Jupyter, Apache Zeppelin, KNIME, and data visualization tools like Matplotlib, contribute to a diverse ecosystem.
Editing and fine tuning existing models is crucial in data science, enabling researchers to adapt pre-existing models to specific use cases. Hugging Face provides pre-trained models for natural language processing that can be fine-tuned, saving time and resources while promoting knowledge sharing among data scientists. This ability to edit and fine-tune models is essential, and Hugging Face simplifies the process for researchers and practitioners.
Why is a Data science platform important?
In summary, an effective data science process demands tools that are easily consumable, eliminating concerns about assembling components, compliance policies, and organizational barriers. Having a data science platform is crucial in meeting these needs by providing a secure connection to data and consolidating all necessary tools and technologies in one accessible place.
Open-source alternatives offer the advantage of customization, allowing users to tailor and expand features to suit specific use cases, offering flexibility and the freedom to select preferred tools and libraries. These open-source platforms not only cater to data scientists on a budget but also fosters a sense of community and collaboration. Open Data Hub is a good example of such platforms.
It is important to be able to use the tools seamlessly without worrying about integration, compliance policies, or organizational obstacles; there is therefore a collective call for secure data and tools access through a platform that supports open-source versions of tools. The aspiration is to maintain control and improvement of the toolset according to evolving needs, with each data scientist playing a role in pushing for advancements. This collective responsibility aims to drive the next phase of evolution in data science, shaping the industry to meet the unique requirements of its practitioners. OpenShift AI is exactly the platform that would cover those concerns. Using OpenShift as the foundation, it is based on Open Data Hub and as such gathers many open source tools into a single coherent platform. Openshift AI is crucial for modern data science due to its comprehensive reference architecture, cloud-native open-source components on top of OpenShift, and coverage of the complete MLOps lifecycle. The platform leverages existing technologies and integrates with certified hardware and software products from partners into one cohesive experience, simplifying the data science workflow and promoting efficiency.
An open-source data science platform provides the tools and resources necessary to achieve these goals and advance the field of data science. So, let’s get started and collaborate with others to make meaningful contributions to this growing community! Whether you are an experienced data scientist or just starting out, there are opportunities for everyone to learn, contribute, and make a difference. Join us in this exciting journey of exploration and discovery, and let’s work together to build a better future through data science!