
A Guide to Seamless Connectivity in OpenShift and OKD
In today’s rapidly evolving technological landscape, the integration of complex architectures into our systems is becoming more prevalent than ever. One of these challenges is to consolidate a multi-cloud architecture into a true hybrid cloud one. In this blog post we will delve into the motivations, solutions, and considerations surrounding the split of services or apps across multiple clusters and explore three different solutions for this.
Motivation for Multi-Cluster Architecture
The primary motivation for splitting applications across different clusters, especially in various cloud environments, revolves around efficiency, stability, cost-effectiveness, and the commitment to providing customers with a reliable service. Various scenarios, such as GDPR compliance, avoiding vendor lock-in, and mitigating risks associated with a single cluster failure, contribute to the decision-making process. Another reason, one of my personal favourites, is a central hub cluster providing services to other clusters. This can involve central secret management with a vault, providing a single pane of glass for security appliances or a platform to run your automation for the complete infrastructure.
Challenges and Solutions
Multi-Cluster App Storage and Management
One of the challenges with distributing services and applications across several clusters is that it increases complexity and some things need to be taken into consideration.
- Multi-cluster App-Storage
This can be addressed by several means. With Ceph it is possible to build metro clusters or stretched clusters. There are several solutions provided by different storage providers. This is not in the scope of this blog article, but is something that needs to be taken into consideration as moving data in or out of a cloud environment comes with additional costs. - Multicluster-App Management
This is something that requires a careful architectured Software delivery pipeline. It’s no rocket science but something that is crucial for the success of a real hybrid cloud strategy. - Multi-Cluster-App-Konnektivität or Multi-Service Connectivity
Ensuring seamless connectivity across clusters or services within a multi-cluster setup is decisive. There are a lot of solutions available. This blog post will highlight the ones supported in OpenShift and available in OKD without too much of an effort.
Easy path out – exposing all services publicly
The simplistic approach of making all services publicly accessible raises significant security concerns.
In exposing all services, you might make your sensitive data available to the world. Take as an example exposing databases publicly. This can lead to several scenarios. First a misconfiguration happens. This can be an easy-to-brute-force password which slips QA or a complete unrestricted access to the data. All of this happened in the past with some prominent examples. Second a zero-day bug is affecting the service behind the endpoint and by exposing it publicly it’s way easier to exploit. Third is the patching cycle. In an ideal world all security patching would happen when the errata is released. Unfortunately we are not living in one and by exposing the services the attack surface is increased unnecessarily.
One way to mitigate this, is to ensure a one-to-one relationship. Among other means that can be accomplished by:
- Using Network Policies. The challenge here is, they are meant for regulating internal access, not external access, i.e. there is not the same granular control as with real firewalls
- Using external systems. The challenge here is, firewalls are normally working on layer 4 and k8s is relying on layer 7 for communication. With Application Level Gateway firewalls or proxies this can be addressed but it increases the administrative effort and decreases speed and agility.
Another threat is the infamous Eve dropping in on the conversation of Alice and Bob or to put in other words, man-in-the-middle attacks. Most applications are made for in-cluster communication, i.e. most do not implement mTLS and it is a great effort to add it to the functionality of an application afterwards. It also increases complexity and excellent developers are not always excellent cryptographer and therefore complexity is increased. Increasing complexity leads to an increased attack surface and this is one of the reasons for the often mentioned KISS-principle which should always be adhered to.
One more thing. You are already in the container/kubernetes world. Why should these challenges be addressed by means of the legacy world if the means to secure the communication are available within this universe?
East-West communication in OpenShift and OKD
To address these challenges within OpenShift and OKD, several Kubernetes-native solutions are available. Let’s explore three of them, which are fully supported in OpenShift and easily implemented in OKD. In this article we will work our way from cluster level, over to application level, up to connecting Service Meshes.
Submariner
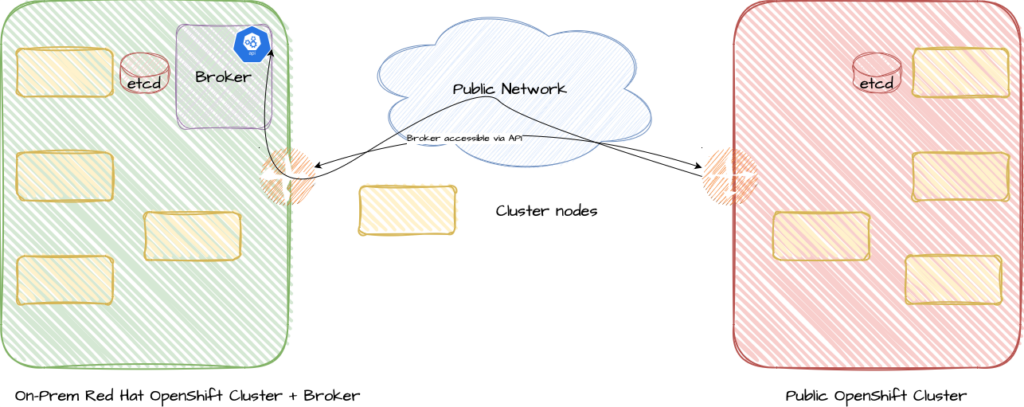
Let’s start at the Cluster level. Allow me to draw the big picture first before going into the technical details.
On a high level a VPN connection is established between two clusters securing the communication and flattening the networks with robust and proven technology. Automatic service discovery is possible but it also allows for restricting what can be consumed from other clusters. Failover scenarios on a service level are possible with Red Hat Advanced Cluster Management (RHACM).
What does it look like in detail?
The central entry point is the broker. The broker is installed in a so-called hub cluster. A hub cluster is a concept that I strongly recommend and its main purpose is to provide shared services for all connected clusters, e.g. secret management via a vault, configuration management or some security applications, and therefore providing a single pane of glass for the complete cluster fleet.
The broker is responsible for establishing and maintaining the connection and for ClusterDiscovery. It provides several Custom Resource Definitions (CRDs) and therefore an API for the components of the submariner deployment.
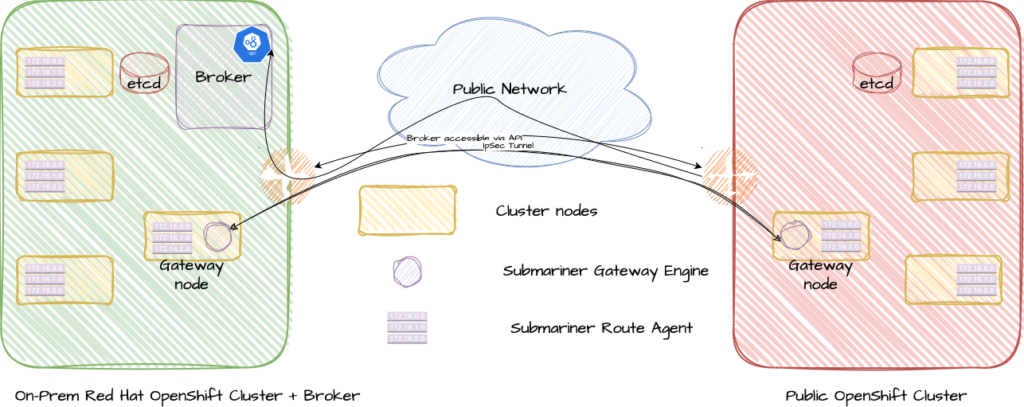
In the next step the communication between the different clusters needs to be established. This happens with the so-called gateway nodes. Any node in the cluster can be a gateway node but there is always only one active. They are running different services to guarantee seamless connectivity. Firstly they host the gateway engine which is responsible for establishing an IPSec tunnel for the secure communication between the entities. Secondly the global net controller is running on them. The global net controller spans a global overlay network including all clusters and addresses the problem of overlapping IP-ranges this way. Every Cluster gets its own range in the network. The final missing piece in this setup is the route agent, which is deployed as a daemon set into every cluster. This is necessary to ensure that network flow will work. The route agents are holding the routing table for the overlay network and are therefore an integral part of the architecture.
What are the benefits of this solution?
In IT as in real life most of what needs to be done breaks down to the simple rule: What is the benefit cost bill? Here are some of the benefits in establishing East-West-Communication with submariner.
- Pod-to-pod and Pod-to-Service routing with native performance.
Submariner eliminates the need for proxies, external load-balancers or special ingress for east-west traffic - Enhanced Security
All traffic between member clusters is encrypted by default with rock-solid and proven technology - Deploy services across clusters
Beyond mere communication submariner also implements cross-cluster service discovery and service failover is possible - Dataplane transparency
Compatible with different cloud providers and network plugins. Therefore it is one step in the way to a true hybrid (multi-)cloud architecture.
Skupper or Red Hat Service Interconnect
For the next solution we will have a look at communication at the Application layer. Unlike submariner skupper needs no administrative privileges. It provides a very flexible solution not stopping connecting clusters but anything that can host a container can be added.
On a very high level a messaging system is used for an encrypted tcp communication, i.e. a layer 7 protocol is used for layer 4 communication. This sounds weird at first, but it has some major advantages.
- For layer 7 communication no administrative privileges are needed. This is normal http(s) communication that is enabled and allowed by default.
- It is completely agnostic of the environment, i.e. different IP versions (IPv4 and IPv6) can be mixed, overlapping IP ranges do not matter.
- It offers high portability and migrating to this solution does not require any network recreation or change of configuration and concepts.
- There is no need for VPN or similar solutions. An application makes a native tcp call to any other application on any other platform and it is forwarded on the http-layer.
On the downside there is a small increase in latency but this should be neglectable for most use cases.
What does it look like in detail?
Please consider the following scenario.
- There is one cluster on a public cloud provider, one cluster in a local datacenter (or a different cloud provider) and one edge device or a VM.
- The cluster in the datacenter is providing a service, e.g. a database that must not run in the cloud because of regulations.
- The service needs to be consumed in the cloud (providing an interface) and data is fed into the database from the edge device.
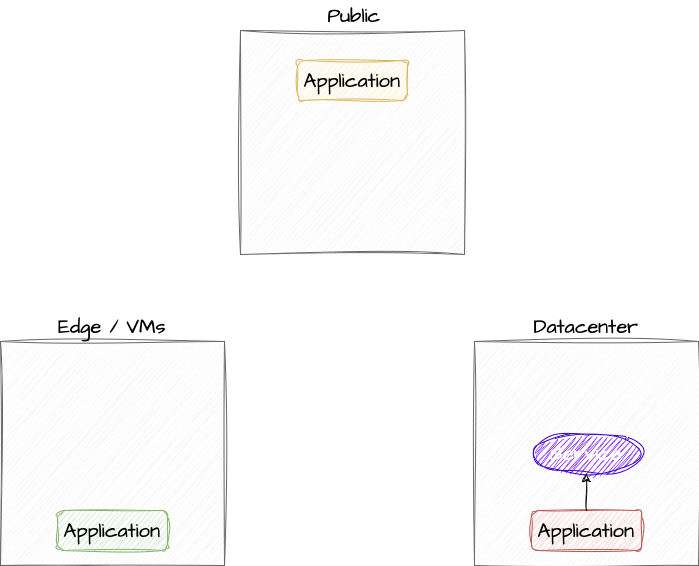
One solution for this could be that the service is exposed on a public endpoint. But this has several security implications. First, it most probably means that you need to expose it via NodePort. For this you need to open the firewall for non-http ports and it means administrative overhead. Secondly a secure communication needs to be in place and this needs to be implemented and maintained. This is something that is very important but unfortunately, often neglected.
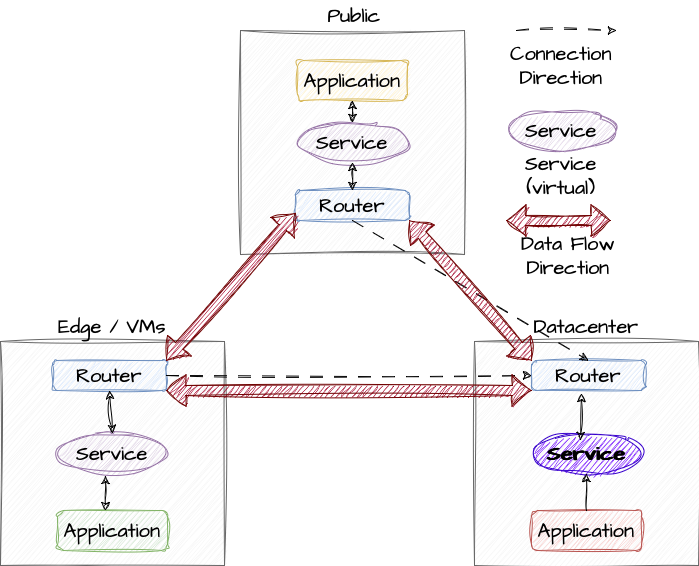
With skupper this can be easily addressed.
- The heart of skupper is the router deployment. It deploys router instances that are based on Apache Qpid Dispatch Router. These routers serve as intermediaries for handling network traffic and facilitating communication between the different applications.
- Skupper provides a command line interface (cli) to configure and manage skupper deployments. This should be mostly used for the initial deployment or troubleshooting. As everything is native kubernetes objects, it is good practice and one of the strengths of the solution to integrate the configuration in a GitOps workflow.
- For transport security TLS is used to ensure confidentiality and integrity of data transmitted between the different devices and clusters.
- Services are made available via ServiceImport configuration. A key and certificate exchange is needed for this. By this it is ensured that only services that are meant to be consumed with skupper can be consumed. Downside is that no automated service discovery is possible.
- Skupper offers two modes of operation, Edge and Interior Mode. Edge mode is simple to set up and establishes a peer-to-peer connection. For more complex scenarios Interior mode is more suited. Here the different applications connect to a central hub cluster (most of the times the cluster in which the provided service resides). In this mode more complex network configurations and routing control is possible.
- This is all done with native kubernetes resources such as Deployments, Services, ConfigMaps and Secrets. So there is absolutely no need for non-kubernetes-native solutions in the architecture.
Something important to be aware of is that you do not have Service Failover like in other solutions but data flow or connection failover.
What are the benefits?
- Simplified Integration
Providing a toolset for easy connectivity without the need for administrative privileges - Flexible Routing
Routes can be configured on various criteria with out of the box failover scenarios - Scalability and Reliability
Load balancing, failover (route) and scalability features ensuring robust and high available solutions without much effort - Kubernetes native solution
All components are kubernetes natives, i.e. it integrates seamlessly into existing tooling and workflows.
Federated Red Hat Service Mesh
The last solution we will examine here is a Federated Service Mesh. Explaining a Service Mesh in detail is out of the scope of this article. There is a lot of documentation and articles about Service Mesh on the internet. For instance this one about Service Mesh for Developers.
In short words, a Kubernetes service mesh works by providing a dedicated infrastructure layer that manages communication between microservices in a Kubernetes cluster. It uses sidecar proxies, a control plane, and a data plane to enable advanced features like observability, security, and traffic management. The benefits of a Service Mesh are as follows:
- Secure service-to-service communication in a cluster with TLS encryption, strong identity-based authentication and authorization
- Automatic load balancing for HTTP, gRPC, WebSocket, and TCP traffic
- Fine-grained control of traffic behaviour with rich routing rules, retries, failovers, and fault injection
- A pluggable policy layer and configuration API supporting access controls, rate limits and quotas
- Automatic metrics, logs, and traces for all traffic within the mesh, including mesh ingress and egress
On the downside complexity is increased a lot and you should consider your use case thoroughly, but if in place, it gives you a high level of security and observability.
So what is a Federated Service Mesh? On a high level it is a distributed networking solution that seamlessly connects, manages and secures microservices across multiple Services Meshes, enabling efficient communication and control while maintaining autonomy of the member meshes.
To fill this abstract description with some life, let’s consider the following scenario:
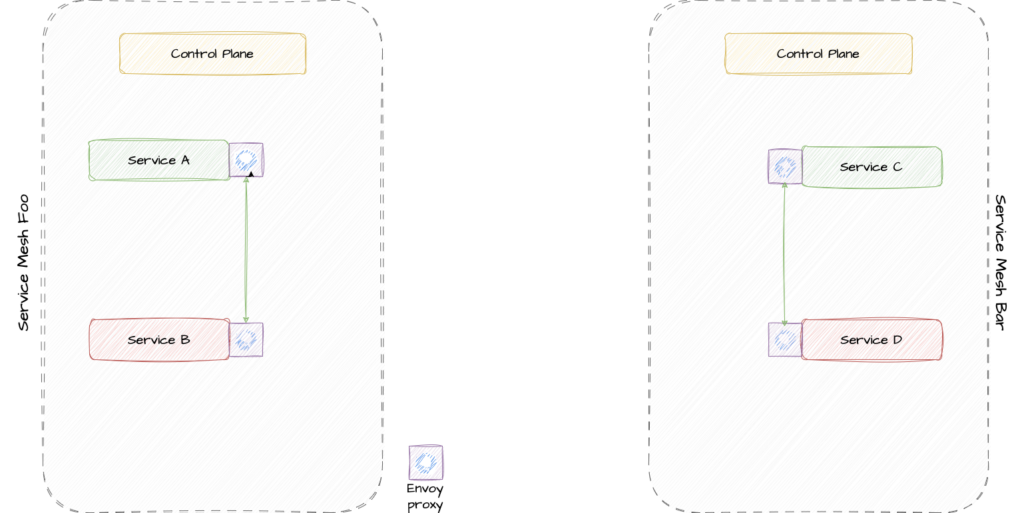
There are two clusters with a Service Mesh deployed. In the Service Mesh Foo Services A and B are able to communicate with each other and in Service Mesh Bar Services C and D are members of the mesh. Service A and Service B need to communicate with each other but B and D should be only able to communicate within their meshes. We already have a mesh in place so we can implement it by federating the two meshes and do not need to reach it by implementing submariner and network policies. But how is this done on a technical level?
- The control plane needs to be configured for a federated mesh. That includes creating additional gateways. In this configuration step you specify
- The ports for communication
- The names of the member meshes, optionally but highly recommended for troubleshooting
- The name of the networks, again optionally but highly recommended
- Name of the egress and ingress gateways
- A trust domain for every mesh in the federation
What is important to understand here, is that two additional gateways are created. Every service mesh contains already an ingress and egress gateway. They are for application communication to and from the outside world, i.e. north-south communication. Federation gateways are strictly used for east-west communication and therefore a separation of the network flow is guaranteed and increases security in communication.
- Creating the above configuration is not sufficient to establish communication. Additionally discovery, the access to the peer mesh and the certificates to validate the other mesh’s clients need to be defined. That is done with the ServiceMeshPeer CRD. Meshes are always defined on a one-to-one basis, i.e. every member of a federated mesh must be made imported into every member it needs to communicate to. Communication between two meshes with a third one acting as a proxy is, for security reasons, not possible. To instantiate the ServiceMeshPeer CRD you need to define the following parameters for it:
- Name of the peer mesh
- Namespace where the Service Mesh control plane is installed
- The remote address
- The port on which addresses are handling discovery requests
- The port on which addresses are handling service requests
- Name of the ingress gateway
- Name of the egress gateway
- The trust domain
- The client ID
- The root certificate to validate the peer member of the federation
- Now that the meshes know each other we need to configure the services that are allowed to talk to each other. That has to be done explicitly and they need to be exported and imported in each member of the federation with the ExportedServiceSet and ImportedServiceSet CRD. This is a point that I really want to emphasise. Exporting one service in mesh Foo is not enough to make it accessible in mesh Bar. It needs to be imported there as well. This increases security but also administration effort.
- Services with the same name can be configured for failover if one mesh suffers from an outage.
As pictures say more than a thousand words. Please take a look at the final picture of a federated Service Mesh
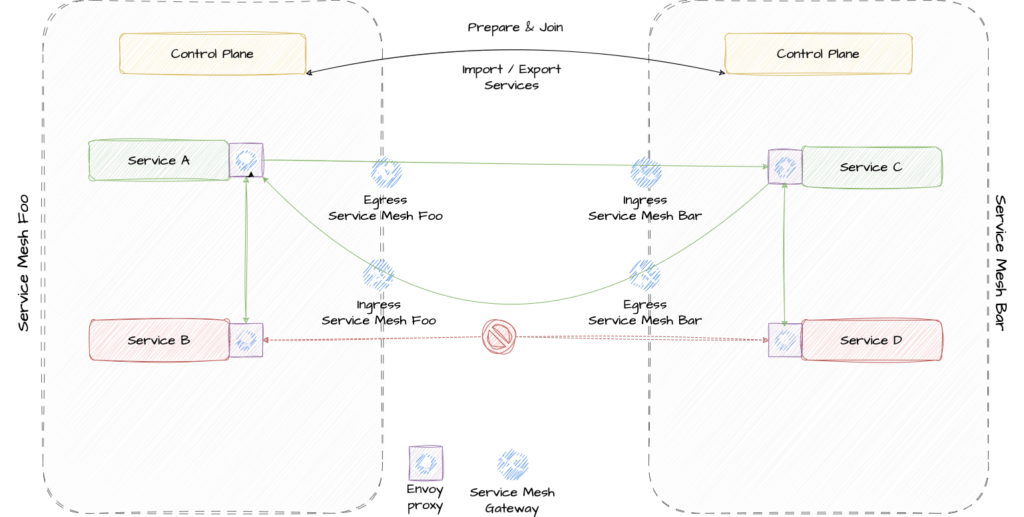
What are the benefits of this solution?
Even though this is the most complicated solution of the three presented, it makes a lot of sense if there are already Service Meshes in place and it provides a consistent and secure way to expand these. But there are more benefits to this solution.
- Multi-Cluster Microservices
Seamlessly deploy and manage microservices across multiple kubernetes clusters and build distributed applications. - Enhanced communication
Simplified cross cluster communication that maintains security and reliability - Traffic management
Sophisticated traffic management including load-balancing, routing rules and failover possibilities - Observability and Monitoring
Comprehensive observability to gain insights into the behaviour and performance of the microservices and network flows
Conclusion
In this article we explored three different solutions to establish east-west communication across multiple kubernetes clusters. All three of them have very different approaches and work on different levels. Each of these solutions have different use cases even if they reach the same goal. Careful consideration of your use case is key to an effective and successful implementation. Here is a short overview of the use cases to help in decision making
| Submariner | Service Interconnect / Skuper | Federated Service Mesh / Istio |
| Cluster scoped interconnect | Application scoped interconnect | Mesh scoped interconnect |
| Regulated industries | Great flexibility | Highly regulated industries |
| Automated Service discovery is needed | Quick to set up | Observability without effort |
| Data plane transparency | Integrates in existing CI/CD | Autonomous handling of meshes is required |
| Centrally managed | K8s native solution required |
Choose the one that fits best into your architecture and use case and go another step to a true hybrid cloud solution.