
tl;dr
The rise of AI, particularly large language models (LLMs) like ChatGPT, has been transformative, making advanced technology accessible and widely used. However, with their growing adoption comes a pressing concern: the sustainability of their energy consumption. This article explores a practical approach to evaluating the power usage of different LLMs using a sample chatbot application deployed on OpenShift. By employing Project Kepler, an initiative leveraging Linux tools to monitor power consumption at the container level, we tested various models (Granite7B-lab, Mistral, Llama2, Llama3) to compare their energy efficiency. Our results showed minimal differences in power usage, but highlighted the potential for significant energy savings. The goal is to raise awareness about the sustainability impacts of AI and encourage further exploration in this area.
Intro
Ladies and gentlemen, the hype is real.
Chatbots, large language models (LLMs), and AI is all over the place – and this is not going away soon. The beautiful thing about it is the speed, scale and simplicity to actually get your hands on state-of-the-art technology. Since it is widely available, almost everyone has already tried using ChatGPT, a lot of people use it already for daily activities and a significant number of enthusiasts are deploying their own LLMs adapting them for various use cases.
One thing you can’t miss while interacting with a chatbot is definitely the afterthought about performance and energy consumption. Just push it into a cloud so you don’t have to worry about it? Sounds too easy. Especially recently, a lot has happened and almost all of the largest enterprises have sustainability, including in IT, as part of their ESG corporate goals. How sustainable are LLMs and how much transparency can we actually get? This is definitely a topic which will get more and more attention over time. In this article I would like to showcase how simple it may be to at least start evaluating the power consumption of different models you may want to use in your project.
Key ingredients or what does a German astronomer have to do with angry llamas?
First of all, let’s take a look at a sample chatbot application we deployed in an OpenShift cluster. It is an example of using the retrieval augmented generation (RAG) technique with open source local LLMs deployed via Ollama – one of the most popular platforms to run local LLMs. Simply put: the query we are sending to the LLM is augmented with context retrieved from documents we provided.
The figure below shows a simple overview of the key components and technologies used:
- Streamlit to implement the chatbot frontend component
- NomicAI as the open source embedding used with Langchain to implement the embedding model
- MilvusDB as our vector store for the knowledge/context
- Ollama to serve local open source LLMs
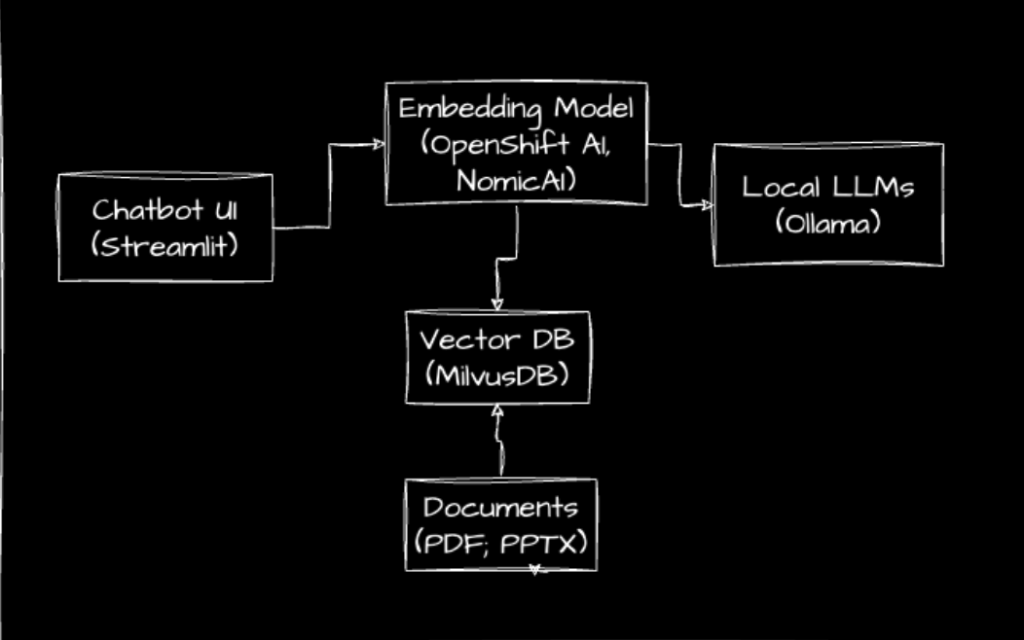
Shoutout to Max Dargatz for implementing this solution in our lab for learning purposes.
Next, what could be the purpose for the bot or, to put it better, what documents could we feed to make it useful? Max came up with another brilliant idea: let’s see if the chatbot could assist us in passing a certification if we give him the course content in PDF format? And so we did! The chatbot received five different chapters of a course on Customer Success Management. Sadly, until now, no one from our team tried to actually pass the exam by using the chatbot – it seemed too easy since it worked quite nicely after some testing. Would it be considered cheating or do we miss some regulation here? 🙂
Now, let’s add the sustainability twist.
Just by using the chatbot without utilizing GPUs, it is easy to notice that each query took some time to respond – usually between 30 and 90 seconds. Not really the user experience you would like to have. Definitely, for serious, production usage, GPUs are currently a must-have when it comes to model inference. But since GPUs are the most wanted piece of hardware today, with a significant price tag, I assume a lot of learning, testing and development will still be done using good old CPUs.
The clear question arose: What about the electricity we are consuming for each query? I could quickly observe huge spikes of CPU utilization in the Ollama pod each time the model was generating an answer. Luckily, a good old German astronomer is here to help. Meet Project Kepler.
Project Kepler – helping cloud native projects meet sustainability goals
Due to my background in Linux Performance analysis, Kepler immediately caught my attention. Exporting power consumption for bare metal servers was nothing new, but in the world of virtualization and cloud native applications – the complexity was on another level. Utilizing familiar Linux primitives like eBPF (Extended Berkeley Packet Filter) and cgroups, Kepler is able to give us insights into power consumption for each container of our application. Here a snapshot of the description from another fantastic technical overview from a CNCF blog post:
In more details, Kepler utilizes a BPF program integrated into the kernel’s pathway to extract process-related resource utilization metrics. Kepler also collects real-time power consumption metrics from the node components using various APIs, such as Intel Running Average Power Limit (RAPL) for CPU and DRAM power, NVIDIA Management Library (NVML) for GPU power, Advanced Configuration and Power Interface (ACPI) for platform power, i.e, the entire node power, Redfish/Intelligent Power Management Interface (IPMI) also for platform power, or Regression-based Trained Power Models when no real-time power metrics are available in the system.
Once all the data that is related to energy consumption and resource utilization are collected, Kepler can calculate the energy consumed by each process. This is done by dividing the power used by a given resource based on the ratio of the process and system resource utilization. We will detail this model later on in this blog. Then, with the power consumption of the processes, Kepler aggregates the power into containers and Kubernetes Pods levels. The data collected and estimated for the container are then stored by Prometheus.
Another very valuable resource to learn more about it was actually posted on Opensourceres, too.
Since the beginning, Red Hat has been the major sponsor of Kepler and currently it is being implemented as the foundation for Power Monitoring for OpenShift. Still in Tech preview, it is available for installation as a regular operator.
Luckily, with our sample RAG application running in an OpenShift bare-metal cluster, it was quite easy to start evaluating the power consumption. Kepler is also capable of monitoring virtualized and cloud environments but in that case it utilizes regression-based trained power models to estimate the power consumption since there is no direct access to the real-time reporting power consumption APIs from the hardware (like Intel RAPL, ACPI or Nvidia NVML).
Besides the typical observability dashboards, now we got additional Power Monitoring pre-built dashboards which will provide us just enough information to get started.
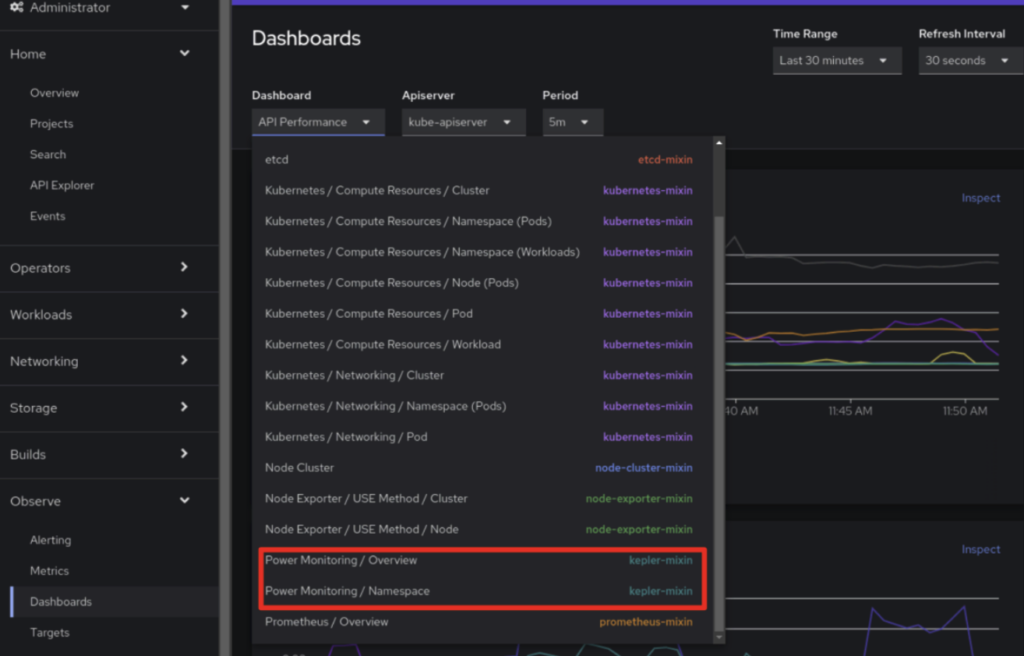
Hey, what about GPUs?
Today, GPUs are typically the preferred option for most model training and inference activities. In this quick example, however, no GPUs were available. Comparing the performance with GPUs in a future study would be an interesting and valuable endeavor. However, Kepler is able to report GPU power consumption data using NVIDIA Management Library (NVML) for GPU power. Support for other vendors is on the roadmap.
The pre-integrated Power Monitoring dashboards in OpenShift will show GPU power consumptions automatically if the data is available.
Connecting the dots
The beautiful thing with Ollama is the simplicity of pulling and switching between different local LLMs. So my goal was to test a few of them to determine whether there is any difference in terms of power consumption while giving answers to the same question. Here are the four different models I tried out:
- Granite7B-lab (parameters: 6.7B, quantization: Q4_K_M)
- Mistral (parameters: 7.2B, quantization: Q4_0)
- Llama2 (parameters: 6.7B, quantization: Q4_0)
- Llama3 (parameters: 8B, quantization: Q4_0)
The same question was asked four times: How would you compare an account manager with a customer success manager? After each question, the model would be changed. Here is the result:
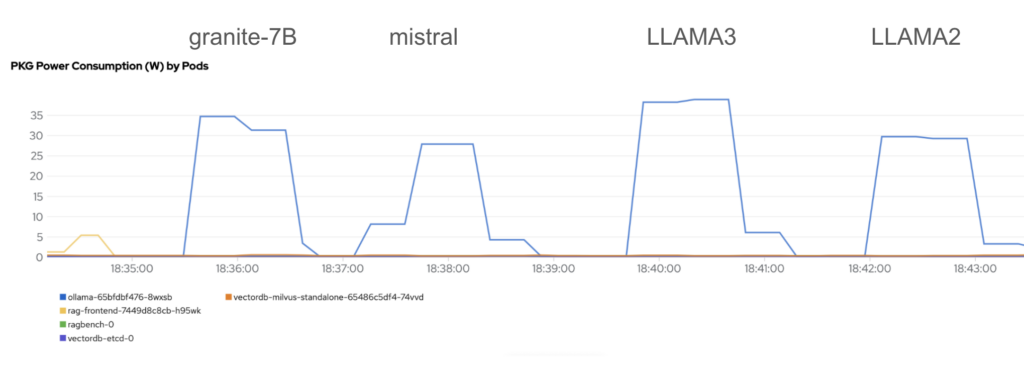
Each model was able to generate a response in a very similar time.
We are able to notice that there is no significant difference between all of the models – ranging between 27 W and 37 W power consumption. However, one could argue that it would be possible to introduce power savings of up to 27% if swapping the worst performing (LLAMA3) with the best performing (Mistral) large language model.
Conclusion
Ideas for further benchmarking are endless: verifying the impact of model size, quantization in use, model type, etc. However, I would like to abruptly stop drawing further performance-related conclusions here as this evaluation was not conducted in any kind of isolated environment and the number of repeated measurements is in no way sufficient to provide confident conclusions. Additionally, the used models have different parameter sizes and different quantization levels. The intention is merely to spark ideas and raise awareness on the fact that we are facing a great expansion of CPU-intensive workloads which could affect the sustainability footprint of enterprise IT today.
Open source large language models are gaining popularity and increasingly adding the needed transparency to the AI ecosystem. Similarly, transparency will hopefully increase when it comes to power consumption of cloud native workloads of tomorrow. The right tools are here already today.